
Obsah
Zdroj: Kran77 / Dreamstime.com
Odnést:
Hluboké modely učení učí počítače přemýšlet samostatně, s některými velmi zábavnými a zajímavými výsledky.
Hluboké učení se používá ve stále více a více doménách a odvětvích. Od automobilů bez řidičů, přes hraní Go až po generování hudby z obrázků každý den vycházejí nové modely hlubokého učení. Zde projdeme několik populárních modelů hlubokého učení. Vědci a vývojáři berou tyto modely a upravují je novými a kreativními způsoby. Doufáme, že vás tato vitrína může inspirovat, abyste viděli, co je možné. (Chcete-li se dozvědět více o pokrokech v umělé inteligenci, přečtěte si článek Bude počítač schopen napodobit lidský mozek?)
Neurální styl
Nemůžete zlepšit své programovací schopnosti, když se nikdo nestará o kvalitu softwaru.
Neurální vypravěč

Neural Storyteller je model, který, když dostane obrázek, může vygenerovat romantický příběh o obrázku. Je to zábavná hračka a přesto si dokážete představit budoucnost a vidět směr, kterým se všechny tyto modely umělé inteligence pohybují.

Výše uvedená funkce je operace „posouvání stylů“, která umožňuje modelu převést standardní popisky obrázků do stylu příběhů z románů. Změna stylu byla inspirována „Neuronovým algoritmem uměleckého stylu“.
Data
V tomto modelu jsou použity dva hlavní zdroje dat. MSCOCO je datový soubor od společnosti Microsoft obsahující asi 300 000 obrázků, přičemž každý obrázek obsahuje pět titulků. MSCOCO je jediná kontrolovaná data, která se používají, což znamená, že jsou to jediná data, do kterých lidé museli jít a explicitně psát popisky pro každý obrázek.
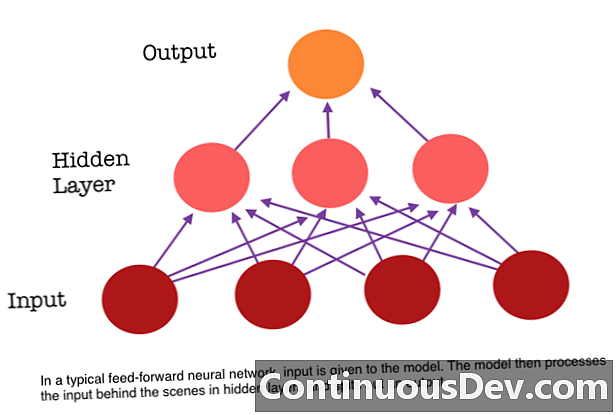
Jedním z hlavních omezení dopředné neuronové sítě je to, že nemá paměť. Každá predikce je nezávislá na předchozích výpočtech, jako by to byla první a jediná predikce, kterou kdy síť vytvořila. Ale pro mnoho úkolů, jako je překlad věty nebo odstavce, by vstupy měly sestávat ze sekvenčních a vzájemně souvisejících údajů. Například by bylo obtížné pochopit jediné slovo ve větě, aniž by to znamenala okolní slova.
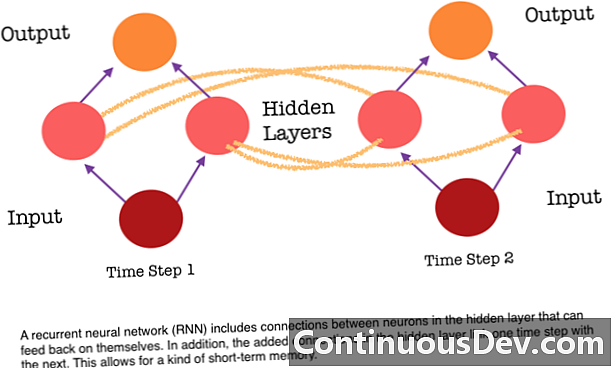
RNN jsou různé, protože přidávají další sadu spojení mezi neurony. Tato propojení umožňují aktivaci neuronů ve skryté vrstvě, aby se v dalším kroku v sekvenci dostaly zpět do sebe. Jinými slovy, v každém kroku skrytá vrstva přijímá jak aktivaci z vrstvy pod ní, tak také z předchozího kroku v sekvenci. Tato struktura v podstatě dává paměti opakujících se neuronových sítí. Takže za účelem detekce objektů může RNN čerpat ze svých předchozích klasifikací psů, aby pomohla určit, zda je aktuální obraz pes.
Char-RNN TED
Tato flexibilní struktura ve skryté vrstvě umožňuje RNN velmi dobré pro jazykové modely znakové úrovně. Char RNN, původně vytvořený Andrejem Karpathym, je model, který bere jeden soubor jako vstup a trénuje RNN, aby se naučil předpovídat další znak v sekvenci. RNN může generovat znak po znaku, který bude vypadat jako původní tréninková data. Demo bylo vyškoleno pomocí přepisů různých TED Talks. Vložte modelu jedno nebo několik klíčových slov a vygeneruje pasáž o klíčových slovech v hlasu / stylu hovoru TED.
Závěr
Tyto modely ukazují nové průlomy ve strojové inteligenci, které se staly možnými díky hlubokému učení. Hluboké učení ukazuje, že dokážeme vyřešit problémy, které jsme nikdy nemohli vyřešit, a dosud jsme nedosáhli této náhorní plošiny. Očekávejte, že v příštích několika letech uvidíte mnoho dalších zajímavých věcí, jako jsou auta bez řidiče, v důsledku hluboké inovace učení.